Merchant Location: Filling in the gaps
In our earlier blogs we’ve discussed creating a training data set and modelling to predict the merchant based on the transaction string. This gets us to a position where we know the date, amount and merchant name for many transactions, but only have partial data on location for some purchases.
Merchant location is valuable information. It allows us to go to a lower level of detail and understand the catchment area and competition between specific sites such Starbucks vs Starbucks and Costa Coffee vs Starbucks. Understanding which stores in a merchant’s estate are doing well and why is critical when making investment decisions.
We are certain where a transaction occurs when we see a store number in a transaction string, or where we see a marker for a place name and a merchant only has one store in that area. Through web scraping, we know that FS269 is a Motor Fuels Group franchised Texaco petrol filling station with Londis and Costa Coffee on site in Kings Langley, Hertfordshire, WD4. We know that Sainsbury’s 4380 is a convenience store in central London.
Composite Image: Motor Fuels Group, Sainsbury’s and Holland and Barrett store finders
How do we calculate the likelihood that this consumer transaction occurred in a specific Holland and Barrett store? We use data science to impute the missing merchant postcode.
We have many pieces of information from our consumer spend panel to draw upon. We infer weekday and weekend location. We calculate distances as the crow flies, by car and by public transport. We know how hundreds of consumers who spend in WD4 on Saturday mornings distribute their spend across the Holland and Barrett estate. We assign a probability to each Holland and Barrett store to fill in the missing merchant location data.
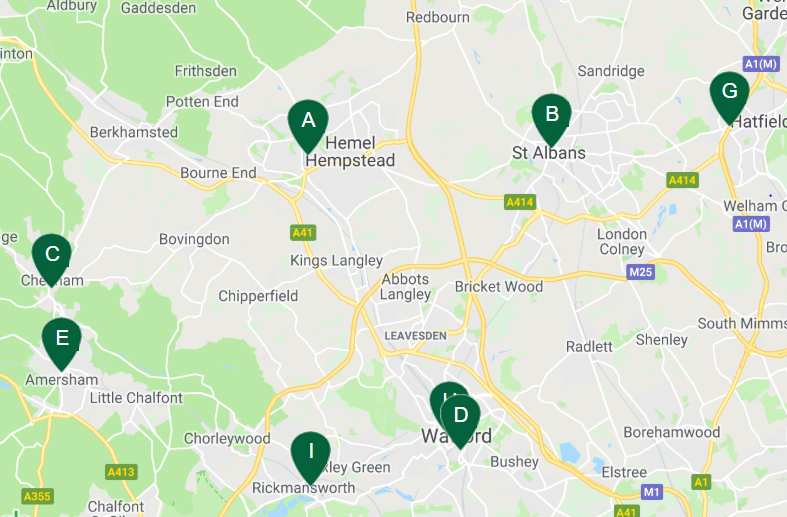
Image: Holland and Barrett store finder
In this example, we predict that the consumer who visited the petrol filling station in Kings Langley, is most likely to have spent at the Holland and Barrett in Hemel Hempstead later in the day. The missing merchant location problem is solved.