Words to Vectors
Manually tagging millions of rows of transactions with their correct merchant group is extremely time consuming and costly, which is why we train models to do this job for us but how does a computer understand text? Enter the world of word embedding, which revolves around representing words as vectors.
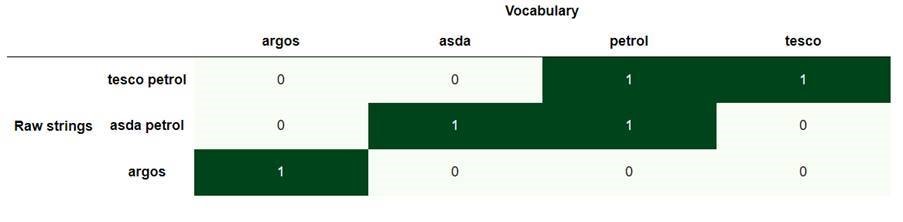
Table shows ‘petrol’ in two different transaction string patterns
Most word embedding techniques rely on a core assumption – words that appear in the same contexts share semantic meaning. In this case we’re less concerned with the semantic meaning and more with how the word is spelt, nevertheless the same reasoning applies. One of these techniques is called bag of words, which represents a text as a set of vocabulary.
To visualise these vectors further, we can apply dimensionality reduction techniques such as T-SNE to summarise these vectors into 3 dimensions. Here we focus on representing asda, tesco, amazon, link/ATM and uber.
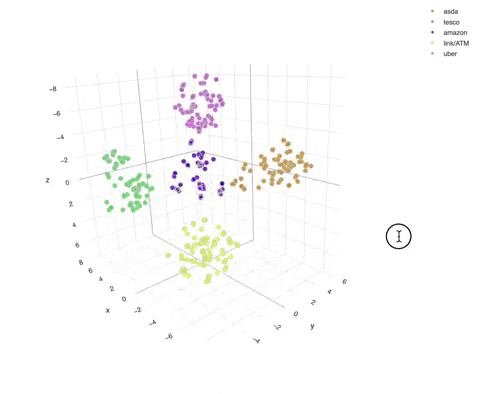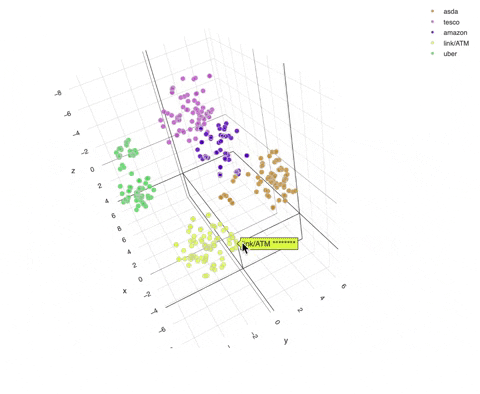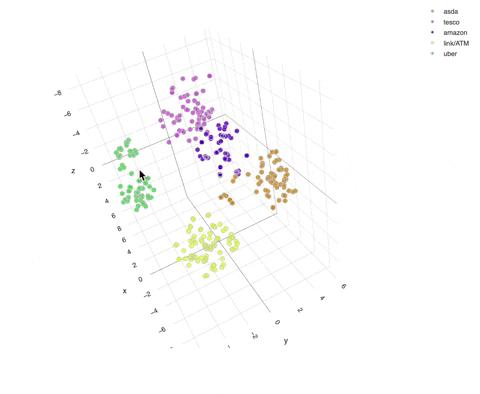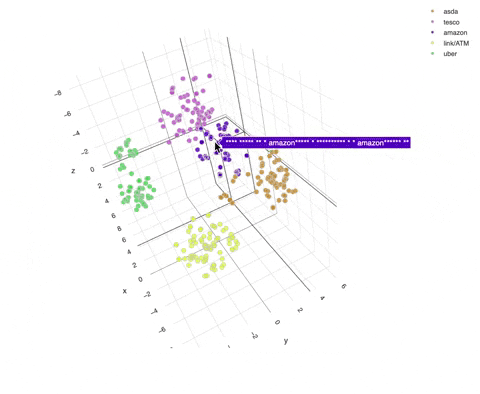
We can see in this visualisation that similar sets of text are clustered closely together, thus allowing us to calculate distances and classify them into their corresponding group.