The Synthetic Data Generation
Improving a model using synthetic training data
Any form of training requires good examples of what is to be learnt, training a machine learning model is no different. The quality of the understanding increases with the quantity and variety of relevant examples that are available. Sometimes however, there may not be a sufficiently large volume of real life examples of a certain type. In this case, we can generate synthetic examples, provided the features of these examples accurately reflect those taken from real life. Take the example of the image of a kitten below. In Figure 1 we see the original image of a kitten. Below this in Figure 2 we can see 6 images that have been generated from the first by doing things like, zooming a bit, turning the head, rotating the kitten slightly. We now have 6 new examples of images of kittens, all different from the first but created using its properties. These can then be used to train a machine learning model to be able to recognise a broader variety of examples.

Figure 1. The original image of a Kitten

Figure 2. Synthetic images of a Kitten, generated from the original image in Figure 1
Our situation for merchants is no different. For some merchants we find we have a large variety of examples on which to train our models, however for others the training set may not be so rich. This leads to a class imbalance which will ultimately affect the overall quality of our model. Below is an example of a vectorised string that we have for Dunelm.
Original String

Original string split into n-grams
This set of n-grams can be converted to a vector as discussed in our Word to Vector blog. This string once represented as a vector sits in vector space alongside all the other real life examples of transactions from Dunelm. In order to generate synthetic samples for this merchant we use the Synthetic Minority Over-sampling TEchnique (SMOTE). This technique imputes points in the vector space that lie between those from real examples as can be seen in Figure 3.
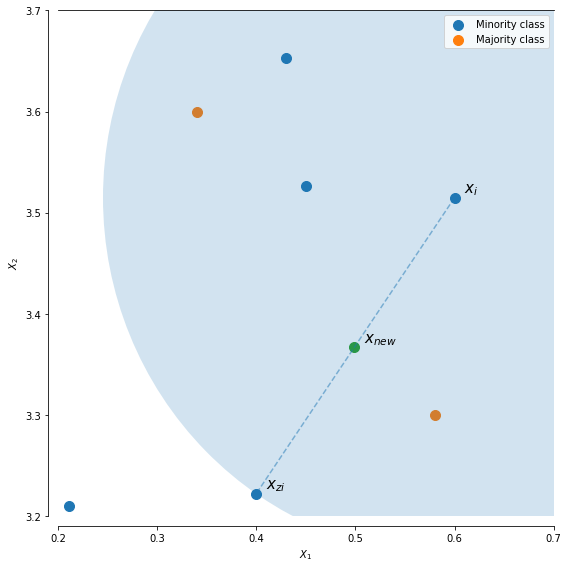
Figure 3. Here we can see how the synthetic instances of the minority class are generated by imputing points between the existing points when using SMOTE
These imputed points in the vector space can then be converted back into n-grams to provide us with the synthetic representations such as that seen below
Synthetic n-gram string
Synthetic strings such as this, along with the real world examples can then be used to train our models, ultimately increasing its effectiveness.